Utiliser Spip comme Backend json

Un cas intéressant d'utilisation de Spip est de le considérer comme un gestionnaire de base de données.
Dans mon cas, je dois séparer (pour des raisons de confidentialités) la saisie de données concernant des événements,
du site principal sur lequel seront affichés les dites données.
Donc d'un côté, j'ai le site principal ABC.com lequel tourne sur Spip.
De l'autre côté, j'ai le site secondaire XYZ.com sur lequel tourne aussi du Spip, mais qui ne doit pas afficher de
données directement.
Préparatifs
Dans un premier temps, je dois rediriger l'ensemble des requêtes d'interrogation du site XYZ.com vers ABC.com, à
l'exception de la partie administration.
Je crée un répertoire squelettes dans l'arborescence SPIP de XYZ.com et y mets un 404.html
Ce fichier sera appelé lorsque l'utilisateur tentera d'afficher des pages de XYZ.com
Le fichier 404.html contient
Ensuite, je dois gérer des événements via Spip sur XYZ.com.
J'ai donc installé le plugin agenda pour gérer des dates associées à un article.
La création d'auteurs, puis d'articles dans Spip ne pose pas de problèmes particuliers ensuite.
Principe de fonctionnement
Pour faire dialoguer XYZ.com et ABC.com, à l'aide de la communauté Spip, j'ai pris l'option JSON.
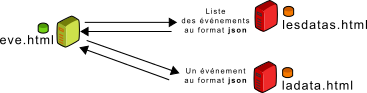
Le fonctionnement est le suivant :
– Une page lesdatas.html sur le site XYZ.com liste les événements et leurs
données principales, au format JSON
– Une page ladata.html sur le site XYZ.com donne les informations concernant un
évenement, au format JSON
– Un mécanisme sur ABC.com lit les pages précédentes. Ce mécanisme se base
sur un modèle Spip, afin d'être utilisable par des rédacteurs dans Spip.
Liste des événements
La liste des événements contient :
– l'identifiant de chaque article/événement
– le titre de chaque article/événement
– la date de chaque article/événement
– le site de chaque article/événement
La page lesdatas.html qui liste les 15 prochains événements se trouve dans le répertoire squelettes et contient :
Lecture des données
Côté ABC.com, un modèle permettra à un rédacteur d'inclure les informations sur les prochains
événement.
Ce modèle va lire les données au format JSON et générer un tableau.
La page eve.html se trouve dans le répertoire /squelettes/modeles et contient :
Inclusion dans le site ABC.com
Le rédacteur Spip sur ABC.com intègrera la liste générée via la balise
dans son article.